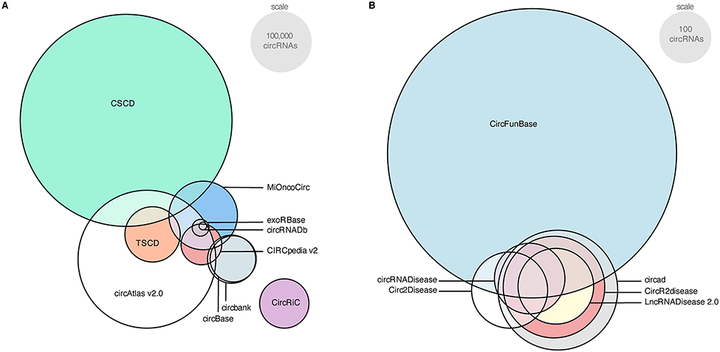
 Varying degrees of overlap within (A) noncurated(B) curated circRNA databases.
Varying degrees of overlap within (A) noncurated(B) curated circRNA databases.
Abstract
Circular RNAs (circRNAs) are covalently closed RNA molecules that have been linked to various diseases, including cancer. However, a precise function and working mechanism are lacking for the larger majority. Following many different experimental and computational approaches to identify circRNAs, multiple circRNA databases were developed as well. Unfortunately, there are several major issues with the current circRNA databases, which substantially hamper progression in the field. First, as the overlap in content is limited, a true reference set of circRNAs is lacking. This results from the low abundance and highly specific expression of circRNAs, and varying sequencing methods, data-analysis pipelines, and circRNA detection tools. A second major issue is the use of ambiguous nomenclature. Thus, redundant or even conflicting names for circRNAs across different databases contribute to the reproducibility crisis. Third, circRNA databases, in essence, rely on the position of the circRNA back-splice junction, whereas alternative splicing could result in circRNAs with different length and sequence. To uniquely identify a circRNA molecule, the full circular sequence is required. Fourth, circRNA databases annotate circRNAs’ microRNA binding and protein-coding potential, but these annotations are generally based on presumed circRNA sequences. Finally, several databases are not regularly updated, contain incomplete data or suffer from connectivity issues. In this review, we present a comprehensive overview of the current circRNA databases and their content, features, and usability. In addition to discussing the current issues regarding circRNA databases, we come with important suggestions to streamline further research in this growing field.
Pieter-Jan Volders
PostDoctoral Fellow (07/2011-02/2022)
LncRNA aficionado working with transcriptomics and proteomics